
serendipity
하둡 Ecosystem 본문
하둡 에코시스템이란?
하둡과 관련된 프레임워크들로, 하둡 코어 프로젝트 & 하둡 서브 프로젝트로 구성된다.
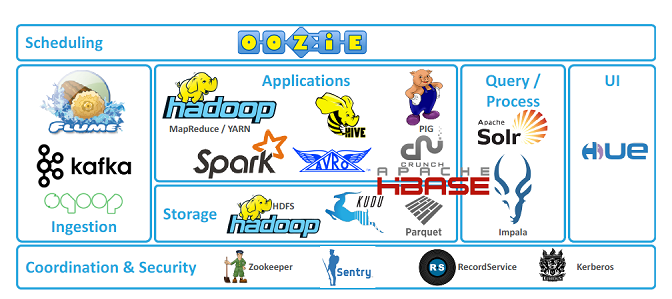
1) 분산 코디네이터
-Zookeeper
분산 환경에서 서버 간 상호 조정이 필요한 다양한 서비스를 제공하는 시스템이다.
분산 동기화를 제공하고 그룹 서비스를 제공하는 중앙 집중식 서비스로 적절한 분산처리
및 환경을 구성하는 서버 설정을 통합적으로 관리한다.
2) 분산 리소스관리
-YARN
작업 스케줄링 및 클러스터 리소스 관리를 위한 프레임워크다.
(맵리듀스, 하이브, 임팔리, 스파크 등 다양한 애플리케이션들은 yarn에서 작업을 실행)
-Mesos
:클라우드 환경에 대한 리소스 관리
Linux 커널과 동일한 원칙을 사용하며, 컴퓨터에 API를 제공
(API는 ex. hadoop,kafka,spark 등)
3) 데이터 저장/적재
-Hbase (분산 데이터베이스)
구글 Bigtable을 기반으로 개발된 비관계형 데이터베이스다.
-HDFS (분산 파일 데이터저장)
애플리케이션 데이터에 대한 높은 처리량의 접근 액세스를 제공하는 분산파일 시스템
-Kudu (컬럼 기반 스토리지)
에코시스템에 새롭게 추가되어 급변하는 데이터에 대한 빠른 분석을 위해 설계되었다.
4) 데이터 수집
- Flume
많은 양의 데이터를 수집 및 집계, 이동하기 위한 분산형 서비스다.
- Chukwa
분산 환경에서 생성되는 데이터를 안정적으로 HDFS에 저장하는 플랫폼
(대규모 분산 시스템 모니터링하기 위한 시스템)
-Scribe
페이스북에서 개발한 데이터 수집 플랫폼으로 chuckwa와 다르게 데이터를 중앙
서버로 전송하는 방식으로 최종 데이터는 다양한 저장소로 활용가능하다.
- Kafka
데이터 스트리밍을 실시간으로 관리하기 위한 분산 시스템이다.
5) 데이터 처리
- Spark
대규모 데이터를 처리하기 위해 빠른 속도로 실행시켜주는 엔진이다.
- Hive
하둡 기반 데이터 솔루션으로 페이스북에서 개발한 오픈소스다.
- Mapreduce
대용량 데이터를 분산처리하기 위한 프로그램으로 정렬된 데이터를 분산처리하고 이를 합친다.
- Impala
하둡 기반 분산 엔진으로, 맵리듀스가 아닌 C++로 개발한 인 메모리 엔진을 사용해 빠른성능을 지닌다.
- Pig
하둡에 저장된 데이터를 맵리슈드 프로그램 만들지 않고 SQL과 유사한 스크립트를 이용해 데이터를 처리한다.
'Study > Big Data' 카테고리의 다른 글
| Kafka 카프카 (0) | 2022.01.25 |
|---|---|
| Flume 플럼 (0) | 2022.01.25 |
| Hadoop 하둡 (0) | 2021.08.24 |
| Matplotlib (0) | 2021.07.10 |
| Pandas 판다스 (0) | 2021.07.10 |



