
serendipity
트랜스포머 네트워크 본문
4. 트랜스포머 네트워크
구글 연구 팀이 NIPS에 공개한 딥러닝 아키텍처로, 뛰어난 성능으로 주목받았다.
이후 발표된 GPT, BERT 등 기법은 트랜스포머 블록을 기본 모델로 쓰고 있다.

- Scaled Dot-Product Attention
트랜스포머 블록의 주요 구성 요소 중 하나다.
입력(X)은 기본적으로 행렬 형태를 가지며 그 크기는 입력 문장의 단어 수 X 입력 임베딩의 차원 수다.
예로, 드디어 /금요일/ 이다 라는 문장이 입력으로 들어가면, 히든 차원 수가 768일 때, 입력 행렬의 크기는 3 X 768이다.
매커니즘은 쿼리(query), 키(key), 값(value) 세가지 사이의 다이내믹스가 핵심이다.
아래 그림의 과정처럼 계산을 수행하며, 소프트맥스 행렬과 값 행렬을 내적하는 것으로 마무리된다.
이것이 단어들 사이 의미적, 문법적 관계를 도출해낼 수 있는 까닭은 다음과 같다.
- dot-product
: 코사인 유사도를 구할 때 내적을 이용하듯이 쿼리와 키의 내적 계산을 통해 벡터 공간상 가까운 정도를 계산한다.
내적 값이 커지는 방향으로 학습이 진행된다. - attention
: 쿼리 단어들과 키 단어들이 일치하는 attention을 self-attention이라고 한다.
같은 문장 안에서 모든 단어 쌍 사이 의미, 문법적 관계 도출한다. - scale
: 키 행렬 차원 수 (d_k) 제곱근으로 나눠 스케일을 맞춰준다.
이는 쿼리-키 내적 행렬 분산을 줄여 softmax gradient가 지나치게 작아지는 것을 방지한다.
Attention을 계산하는 식에서 softmax 확률은 가중치 역할을 하고 각 값 벡터를 가중합한다고 볼 수 있다.
각 값 벡터들이 쿼리-키 단어에 해당하는 softmax 확률에 곱해진 뒤에 모두 더해지는 것이다.
Self Attention의 장점
| 다른 모델 | Self Attention |
| CNN : 사용자가 정한 특정 window 내 로컬 문맥만 확인 | 문장 내 모든 단어 쌍 사이 관계 전체 파악 |
| RNN : sequence 길이가 길면 vanishing gradient 문제 발생 |
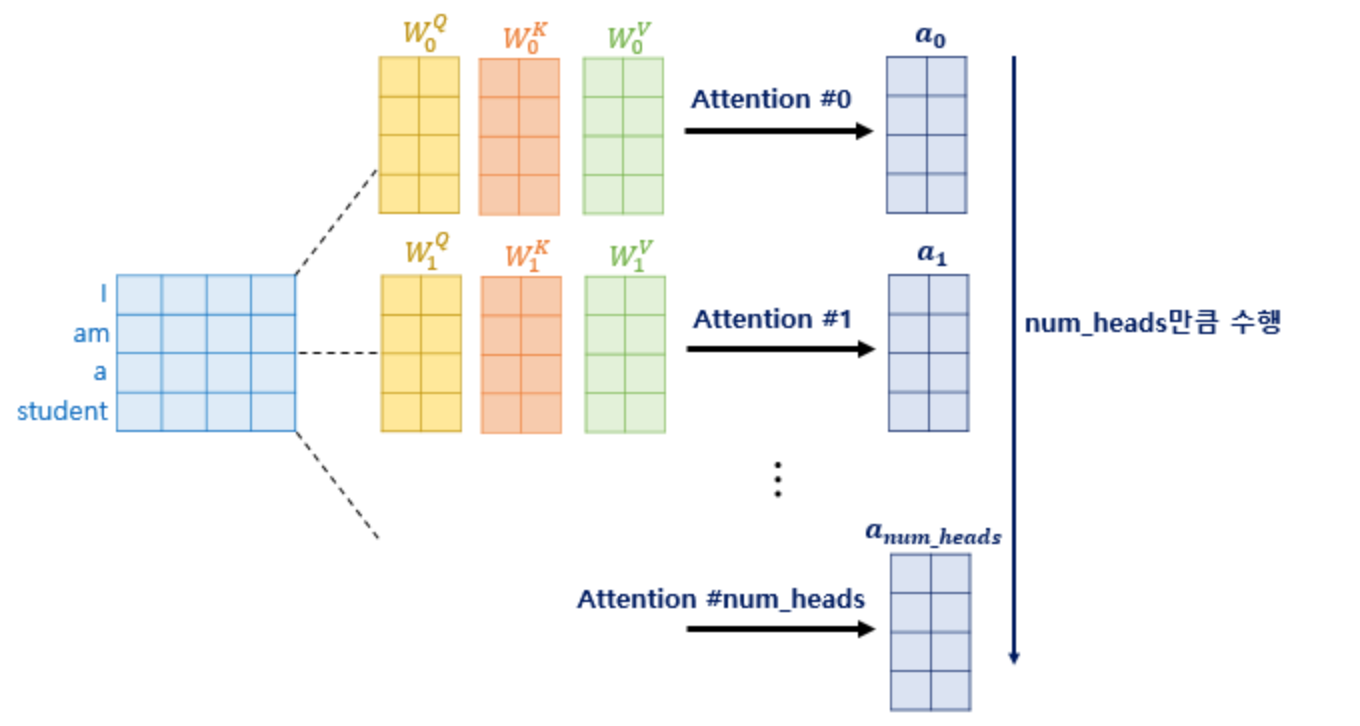
- Multihead Attention
위에서 언급한 Scaled Dot-Product Attention을 여러번 시행하는 것이다.
앞에서 만든 쿼리(Q), 키(K), 값(V)에 Scaled Dot-Product를 h번 진행하고,
각 Attention 결과 행렬을 concatenate하여 W^O와 내적함으로써 행렬 크기를 입력 행렬과 맞춰준다.
( 입출력 행렬의 크기는 (입력 단어 수) * (hidden vector 차원 수)로 동일하다.)
- Position-wise Feedforward Networks
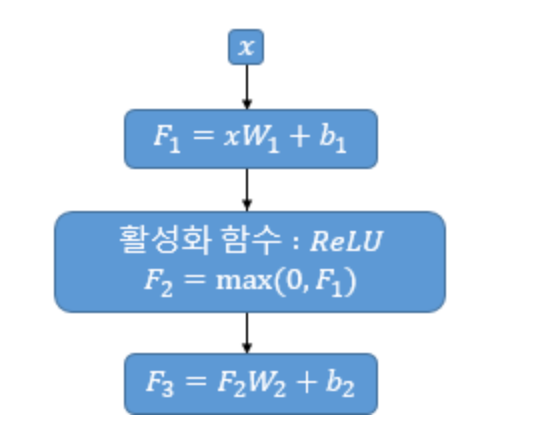
앞의 Multi-Head Attention 출력 행렬을 행 벡터 단위로 수식을 적용한다. 즉, 단어 벡터 x 각각에 수식을 적용하는 것이다.
먼저 선형변환을 한 후, ReLU를 적용시킨 뒤 또 한번의 선형변환을 거쳐 계산된다.
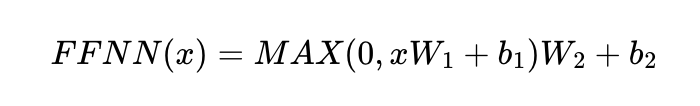
🌱 트랜스포머의 학습 전략은 ' 웜업(warm up) '이다.
사용자가 정한 스텝 수에 이르기까지 학습률을 올렸다가 스텝 수를 만족하면 조금씩 떨어뜨리는 방식이다.
이는 대규모 데이터, 큰 모델 학습에 적합하다.
'Study > AI' 카테고리의 다른 글
| 임베딩 파인튜닝 (0) | 2021.07.13 |
|---|---|
| BERT (0) | 2021.07.13 |
| ELMo (0) | 2021.07.12 |
| Doc2Vec , LDA (0) | 2021.07.12 |
| GloVe , Swivel (0) | 2021.07.11 |



