NPLM , Word2Vec
단어 수준 임베딩 모델 (Word Embedding)
1. NPLM (Neural Probabilistic Language Model)
모델 기본 구조)
기존 언어 모델의 한계 :
- 학습 데이터에 존재하지 않은 n-gram이 포함된 문장이 나타날 확률 값을 0으로 부여하는데,
백오프나 스무딩으로 이런 문제를 일부 보완할 수 있지만 완전한 것은 아니다.
- 문장의 장기 의존성을 포착해내기가 어렵다. 즉, n-gram 모델의 n을 5 이상으로 길게 설정할 수 없다.
- 단어 문장 간 유사도를 계산할 수 없다.
NLPM은 통계 기반의 전통적인 기존 언어 모델의 한계를 일부 극복한 언어 모델이라는 점에서 의의가 있다.
그뿐만 아니라 NPLM 자체가 단어 임베딩 역할을 수행할 수 있다.
NPLM의 학습)
NPLM은 단어 시퀀스가 주어졌을 때 다음 단어가 무엇인지 맞추는 과정에서 학습된다.
직전까지 등장한 n-1개의 단어들로 다음 단어를 맞추는 n-gram 언어 모델이다.

위 모델 구조를 보면, 아래부터 입력을 받아 위에서 출력하는 구조다.
k를 임의의 숫자라고 한다면, w_k은 문장에서 k번째에 등장하는 단어를 말하며 index for w_k은 k번째임을 가리키는 one-hot vector 이다.행렬 C는 각 단어에 대한 벡터가 행으로 쌓여 있는 행렬이며, 초기값은 랜덤으로 부여된다. 또한 t는 예측할 단어가 등장하는 위치이고, n은 입력되는 단어 개수이다. 그래서 t-(n-1)번째부터 t-1번째 단어에 대한 one-hot vector값이 입력으로 들어가게 되는 것이다.
- 입력층 (input layer)
t-(n-1)~t-1번째 단어 벡터 위치를 나타내는 one-hot vector와 행렬 C가 내적으로 곱해지며 해당 단어의 벡터값이 나온다. 나오는 벡터값들을 각각 x_k라고 하며 옆으로 concatenate하여 x로 나타낸다. - 은닉층 (hidden layer)
tanh 함수를 이용하여 score vector 값을 구하며, 공식은(b, W, U, d, H는 매개변수) y = b + Wx + U*tanh(d+Hx) - 출력층 (output layer)
y값에 softmax 함수를 적용시키며, 정답 one-hot vector와 값을 비교하여 역전파(back-propagation)를 통해 학습된다.
NPLM 학습이 종료되면 우리는 행렬 C를 각 단어에 해당하는 m차원 임베딩으로 사용한다.
2. Word2Vec
2013년 구글 연구팀이 발표한 기법으로 가장 널리 쓰이고 있는 단어 임베딩 모델이다.
2개의 논문으로 나누어 발표되었는데, Efficient Estimation of Word Representations in Vector Space(Milkolov et al., 2013a) 에서 Skip-Gram과 CBOW라는 모델이 제안됐고, Distributed Representations of Words and Phrase and their Compos itionality (Milkolov et al., 2013a)에서는 이 두모델을 근간으로 하되, 네거티브 샘플링 등 학습 최적화 기법을 제안하였다.
모델 기본 구조)
Word2Vec은 입력층과 출력층 사이에 하나의 은닉층만 존재하므로 딥러닝 모델이 아니다. 이처럼 은닉층이 1개인 경우는 얕은 신경망(shallow Neural Network)이라고 한다. Word2Vec의 은닉층은 룩업 테이블이라는 연산을 담당하는 투사층(projection layer)이다.
Word2Vec의 종류를 나누자면 다음과 같으며, 서로 학습되는 과정이 반대된다.
CBOW : 주변 문맥 단어(context word)로 타깃 단어(target word)를 맞추는 과정 학습
Skip-gram : 타깃 단어(target word)로 주변 문맥 단어(context word) 맞추는 과정 학습
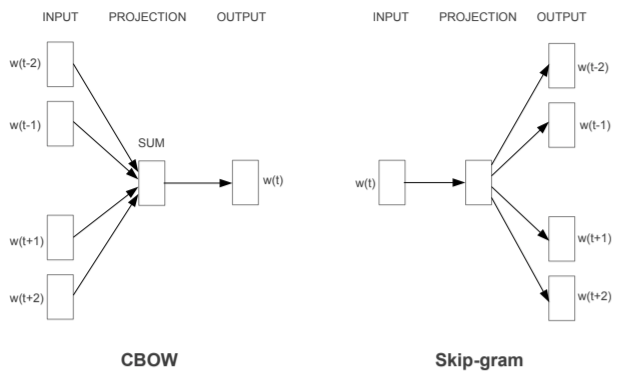
Skip-gram이 같은 말뭉치로도 많은 학습 데이터를 확보할 수 있어 임베딩 품질이 CBOW보다 좋으므로 이에 대해 깊이 알아보고자 한다.
학습 데이터 구축)
전체 corpus를 단어별로 슬라이딩하면서 생성한다. 참고로 Word2Vec 학습을 위한 입력, 출력은 모두 원-핫 인코딩된 데이터다.
Positive sample : (target 단어, 주변에 등장하는 context 단어) 쌍
Negative sample : (target 단어, 주변에 등장하지 않은 단어) 쌍
CBOW는 주변 단어의 원-핫 벡터에 대해 가중치 W를 곱해서 얻은 벡터들은 투사층에서 이 벡터들의 평균 벡터를 구한다.
CBOW와 달리 Skip-Gram은 중심 단어에서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없다.
Skip-gram 모델이 처음 제안된 Mikolov et al.(2013a)에서는 타깃 단어가 주어졌을 때 문맥 단어가 무엇일지 맞추는 과정에서 학습됐다.
하지만 이 방식은 소프트맥스 때문에 계산량이 비교적 큰편이다. Word2Vec은 출력층이 내놓는 스코어값에 소프트맥스 함수를 적용해 확률값으로 변환한 후 이를 정답과 비교해 역전파(backpropagation)하는 구조이다. 그런데 소프트맥스를 적용하려면 분모에 해당하는 값, 즉 중심단어와 나머지 모든 단어의 내적을 한 뒤, 이를 다시 exp를 취해줘야 한다. 보통 전체 단어가 10만개 안팎으로 주어지니까 계산량이 어마어마해지는 문제점이 발생한다.
이후 Mikolov et al.(2013b)에서 이 문제점을 해결하기 위해 제안한 것은 타깃 단어와 문맥 단어 쌍이 주어졌을 때 해당 쌍이 포지티브 샘플(+)인지 네거티브 샘플(-)인지 이진 분류하는 과정에서 학습된다. 이렇게 학습하는 기법을 네거티브 샘플링(negative sampling)이라고 한다. 소프트맥스 확률을 구할 때 전체 단어를 대상으로 구하지 않고, 일부 단어만 뽑아서 계산을 한다.
예를 들어 ‘나는 임베딩 공부를 하고 있다’에서 중심 단어를 ‘임베딩’으로,주변 단어를 ‘나는’과 ‘공부를’이라고 해보자. 실제 주변 단어인 ‘나는’과 ‘공부를’은 긍정적인(positive) 예시가 되고, 주변 단어에 포함되지 않는 ‘하고’와 ‘있다’는 부정적인(negative) 예시가 된다. 이와 같이 부정적인 예시가 적은 경우는 상관없지만, 실제 코퍼스(corpus) 상에서는 부정적인 예시들의 수가 매우 크므로 그 중 일부(sampling)를 뽑아서 사용하는 방법이다. 이 방식은 Positive sample 1개와 Negative sample k개만 계산하면 되어 계산량이 줄어들게 되었다. 논문에 따르면 1회 학습시 사용하는 Negative 샘플의 수는 작은 말뭉치일 경우 5~20개, 큰 말뭉치일 경우 2~5개가 적당하다.

절차는 사용자가 지정한 윈도우 사이즈 내에 등장하지 않는 단어(negative sample)를 5~20개 정도 뽑는다. 이를 정답단어와 합쳐 전체 단어처럼 소프트맥스 확률을 구하는 것이다. 바꿔 말하면 윈도우 사이즈가 5일 경우 최대 25개 단어를 대상으로만 소프트맥스 확률을 계산하고, 파라메터 업데이트도 25개 대상으로만 이뤄진다는 이야기다.
이와 별개로 자주 등장하는 단어는 학습에서 제외하는 서브샘플링이라는 기법도 적용했다. 학습량을 효과적으로 줄여 계산량을 감소시키는 전략이다. 학습 자체를 아예 스킵한다는 점에서 negative sampling과 차이를 보인다.

모델 학습)
타깃 단어와 문맥 단어 쌍이 주어졌을 때 해당 쌍이 포지티브 샘플(+)인지 아닌지를 예측하는 과정에서 학습된다. if 포지티브 샘플이면, 조건부 확률을 최대화해야한다. 모델의 파라미터는 U(타깃단어 대응)와 V(문맥단어 대응) 행렬 두가지다. 둘의 크기는 어휘 집합의 크기 (|V|) X 임베딩 차원 수 (d)로 동일하다. NPLM의 수식과 비교했을 때 학습 파라미터 종류와 크기가 줄어든 것을 확인할 수 있다.
Word2Vec의 Skip-gram은 아래 식을 최대화하는 방향으로 학습을 진행한다. 아래 식 좌변은 중심단어(c)가 주어졌을 때 주변단어(o)가 나타날 확률이라는 뜻이다. 식을 최대화하려면 우변의 분자는 키우고 분모는 줄여야 한다. 분모를 줄이려면 exp(-utvc)를 줄여아하는데, 그러려면 포지티브 샘플에 대응하는 단어 벡터인 u와 v의 내적값을 키워야한다.

! 두 벡터의 내적은 코사인 유사도(Cosine similarity)와 비례한다. 내적 값의 상향은 두 벡터 간 유사도를 높인다. Word2Vec은 중심단어와 주변단어 벡터의 내적이 코사인 유사도가 되도록 단어벡터를 벡터공간에 임베딩한다. 학습 말뭉치를 만드는 방식이나 subsampling, negative sampling 등의 기법을 통해 성능은 끌어올리고 계산복잡성은 낮추었다.
from gensim.models import Word2Vec
corpus = ["문장이","토큰별로","split","되어","있도록"]
model = word2Vec(corpus, size=100, workers=4, sg=1)
# size : 임베딩 크기
# workers : CPU 사용 개수
# sg : 0(CBOW) / 1(Skip-gram)
model.most_similar("찾아볼 단어", topn=5)
Word2Vec의 단점은 다음과 같다.
- 모르는 단어와의 유사도를 계산할 수 없다.
- 희귀 단어의 임베딩 정확도가 낮다.
- 영어가 아닌 언어에 적용하면 문제가 생긴다.