임베딩 파인튜닝
임베딩 파인튜닝
🌱 파인 튜닝이란?
프리트레인 이후 추가 학습을 시행해 임베딩을 다운스트림 태스크에 맞게 업데이트하는 것
전이학습은 BERT의 언어 모델의 출력에 추가적인 모델을 쌓아 만든다. 일반적으로 복잡한 CNN, LSTM, Attention을 쌓지 않고 간단한 DNN만 쌓아도 성능이 잘 나오며 별 차이가 없다고 알려져 있다.
단어 임베딩 활용

1) 입력 문장을 토크나이즈한 뒤 해당 토큰에 대응하는 단어 벡터를 참조해 파인 튜닝 네트워크의 입력값으로 만든다.
2) 단어 임베딩을 1개 층의 양방향 LSTM 레이어에 태우고, 각 LSTM셀에서 나온 출력 벡터들에 어텐션 메커니즘을
적용해 고정된 길이의 히든 벡터로 만든다.
3) 히든 벡터를 활성함수가 ReLU인 피드포워드 네트워크에 입력한다.
4) 피드포워드 네트워크의 출력 벡터인 로짓 벡터에 소프트맥스를 취해 긍정, 부정 2차원 확률 벡터를 만든다.
5) 이를 정답 레이블과 비교해 학습 손실을 구하고, 이 손실을 최소화하는 방향으로 모델 전체를 업데이트한다.
* 이때 업데이트 대상은 단어 임베딩까지 포함하도록 설정한다.
임베딩까지 업데이트하는 기법인 파인 튜닝과 반대로
임베딩은 그대로 두고 위의 레이어만 학습하는 방법을 피처베이스기법이라고 한다.
ELMo 모델 파인 튜닝)
단어 임베딩 튜닝 네트워크와 거의 유사하다. 단어 임베딩 대신 ELMo를 쓴다는 점만 다르다.

BERT 모델파인 튜닝

(a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다.
(b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다.
(c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다.
(d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다.
다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.
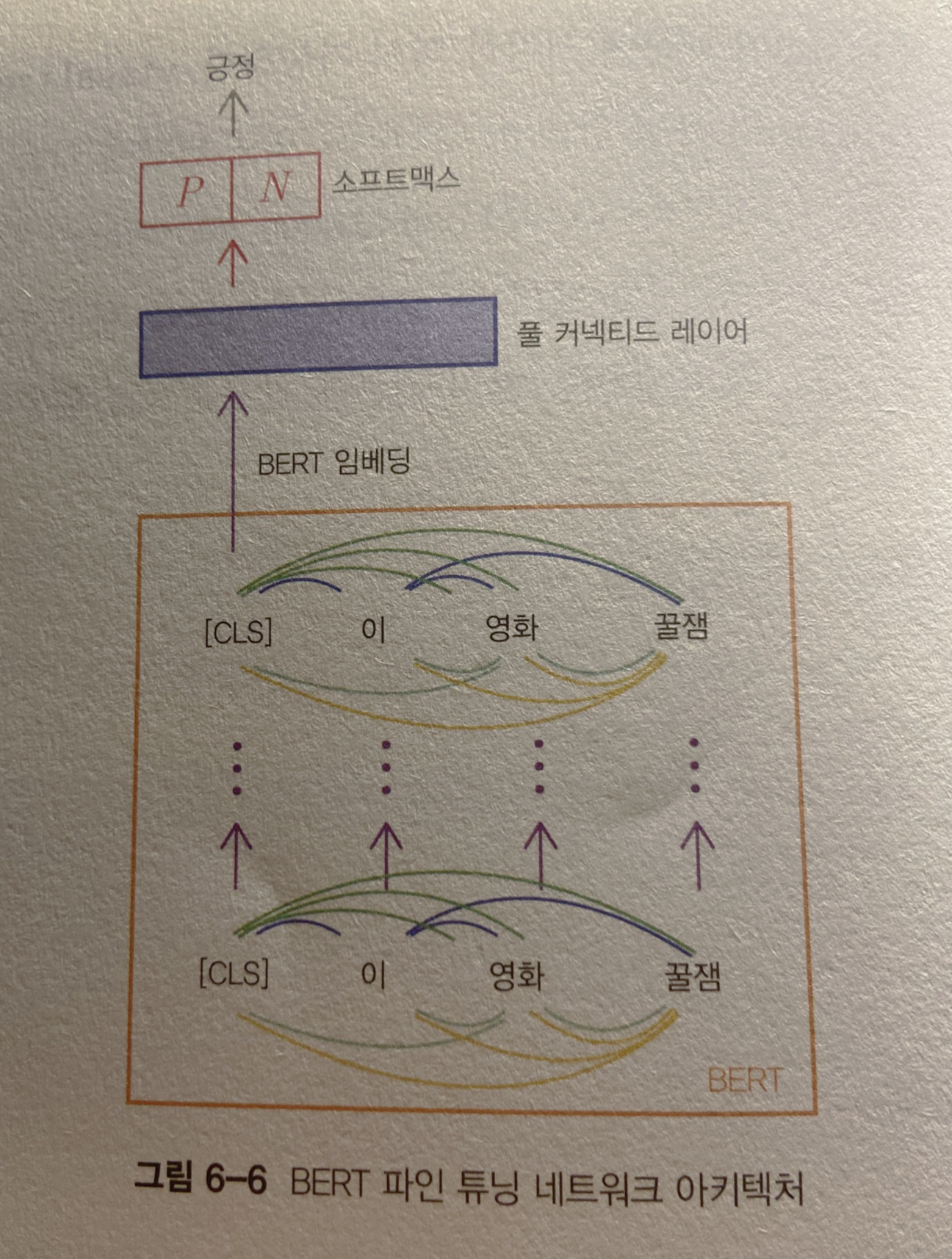
BERT의 파인 튜닝 네트워크는 비교적 간단한 구조다.
BERT 모델에 문장을 입력해 스페셜 토큰 [CLS]에 해당하는 벡터를 추출한다.
트랜스포머 블록은 문장 내 모든 단어 쌍 간 관계를 고려하므로 [CLS] 벡터에는 문장 전체의 의미가 녹아있다.
이 벡터를 1개 층의 풀 커넥티드 레이어를 적용한 뒤 소프트맥스를 취해 2차원의 확률 벡터로 변환한다.
이후 정답 레이블과 비교하여 크로스 엔트로피를 계산하고 이 학습 손실을 최소화하는 방향으로 모델 파라미터들을 조금씩 업데이트한다.
프로빙 모델 (probing model)
임베딩별 성능을 객관적으로 검증하기 위해 제안됐다.

Tenny et al.(2019a)와 (2019b)에 따르면 문장 임베딩 기법이 단어 수준보다 성능이 우월하다.
형태소 분석, 문장 성분 분석 같은 문법 과제는 하위 레이어가
의미역 분석, 상호 참조 해결, 의미관계 분석 같은 의미론적 과제는 상위 레이어가 중요하다.