
serendipity
MapReduce 맵리듀스 본문
맵리듀스란 ?
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작해 2004년 발표한 sw 프레임워크
간단히 설명해보자면 한명이 3주 작업할 일을 3명이 나눠 1주에 다 끝내는 것!
하둡에서 사용하는 병렬처리 개념이며, 3명의 작업자를 클러스터라고 한다.
하둡에서는 계산시 큰 파일을 블럭단위로 나누고 모든 블럭은 같은 Map 작업을 수행하고 Reduce 작업을 수행한다.

[ Input -> Splitting -> Mapping -> Shuffling -> Reducing -> Final Result ]
흩어져있는 데이터를 수직화 -> 데이터를 각각의 종류별로 모음(Map) -> 정렬, 필터링을 거쳐 데이터를 추출(Reduce)
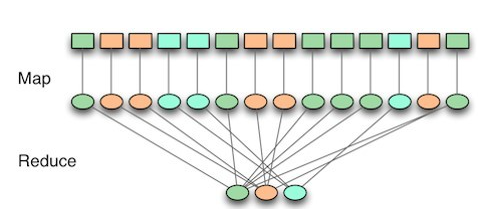
분산형 파일시스템에서 수행되는
① MapReduce 작업이 끝나면 HDFS에 파일이 써지고(write),
② MapReduce 작업이 시작될 때는 HDFS로 부터 파일을 가져오는(Read) 작업이 수행된다.
1) MAP 맵
: key-value 쌍을 처리하는 함수로 중간 결과물 형태의 키/값 쌍 데이터를 만든다.
2) REDUCE 리듀스
: 앞서 중간 결과물의 key를 통해 같은 key를 가진 값들을 합쳐 최종 결과물을 만든다. (중복 제거)
MapReduce System

Client, JobTracker, TaskTracker로 구성되어 있다.
1) Client : 분석하려고 하는 데이터를 Job의 형태로 JobTracker에 전달한다.
2) JobTracker : (Namenode에 위치)
하둡 클러스터에 등록된 전체 Job을 스케줄링 , 모니터링을 수행한다.
3) TaskTracker : (Datanode에 위치)
잡트래커로부터 작업을 요청받고, map & reduce 개수만큼 map task와 reduce task를 생성한다.
잡트래커에게 상황을 보고한다.
장점)
단순하고 사용이 편리하다
특정화된 데이터 모델이나 스키마 정의, 질의 언어에 의존적이지 않다.
병렬 데이터 처리를 윟나 시스템으로 하부 저장구조와 독립적이다.
높은 확장성을 지닌다.
단점)
단순한 인터페이스를 제공함에 반해, 복잡한 알고리즘에는 효율적이지 않다.
DBMS와 비교해 상대적으로 낮은 성능을 보인다.
'Study > Big Data' 카테고리의 다른 글
| HBase (0) | 2022.01.26 |
|---|---|
| Zookeeper 주키퍼 (0) | 2022.01.26 |
| Kafka 카프카 (0) | 2022.01.25 |
| Flume 플럼 (0) | 2022.01.25 |
| 하둡 Ecosystem (0) | 2022.01.10 |



